在人工智能基础软件开发的领域中,PyTorch凭借其直观的编程模型和卓越的灵活性,已成为研究和工业应用的首选框架之一。其核心魅力很大程度上源于其独特的动态计算图机制。本文旨在深入探讨PyTorch中的计算图概念及其动态构建过程,帮助开发者理解其底层原理与优势。
一、 什么是计算图?
计算图是一种用于描述数学运算的有向无环图(DAG),是深度学习框架进行自动微分和梯度优化的核心数据结构。在计算图中:
- 节点(Nodes):代表运算操作(如加法、矩阵乘法)或输入数据(如张量)。
- 边(Edges):代表数据(张量)在节点间的流动方向,体现了运算间的依赖关系。
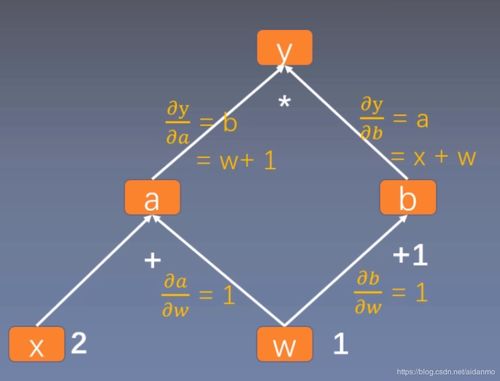
例如,一个简单的线性函数 z = w * x + b 的计算图包含三个操作节点(乘法、加法)和三个数据节点(w, x, b)。
二、 PyTorch的动态图机制
PyTorch采用“动态计算图”(又称“define-by-run”或“即时执行”模式),这与TensorFlow 1.x时代的静态图(“define-and-run”)形成鲜明对比。
1. 动态图的构建过程:
在PyTorch中,计算图是在代码运行时被即时构建的。每当我们对一个torch.Tensor执行一个操作(如+、*、torch.relu),PyTorch会自动在后台创建一个表示该操作的节点,并将其添加到正在构建的计算图中。这个图随着代码的执行而动态生成、变化和销毁。
- 核心组件:
autograd与Tensor
- 当创建一个张量并设置
requires<em>grad=True时(例如x = torch.tensor([1.0], requires</em>grad=True)),PyTorch开始跟踪在其上执行的所有操作。
- 每个这样的张量都有一个
grad_fn属性,它指向创建该张量的Function节点。这个节点记录了生成该张量的操作及其在计算图中的位置。
- 调用
.backward()方法时,PyTorch会沿着这个动态构建好的图,从调用张量开始,依据链式法则自动计算所有requires_grad=True的张量的梯度。
3. 一个简单的动态图示例:
`python
import torch
x = torch.tensor(2.0, requiresgrad=True)
y = torch.tensor(3.0, requiresgrad=True)
# 前向传播:图在每一步操作中动态构建
a = x y # 创建乘法节点
b = a + 1 # 创建加法节点
z = b ** 2 # 创建幂运算节点
# 此时,一个计算图已经隐式构建完成: (x, y) -> mul -> add -> pow -> z
z.backward() # 自动反向传播,计算 x 和 y 的梯度
print(f'梯度 dz/dx: {x.grad}') # 输出: 24.0
print(f'梯度 dz/dy: {y.grad}') # 输出: 16.0
`
在这个例子中,计算图并非预先定义,而是在执行 a = x </em> y 等语句时一步步“画”出来的。
三、 动态图机制的优势
1. 直观灵活,易于调试:
动态图允许使用标准的Python控制流(如if-else条件语句、for/while循环),使得模型逻辑的编写与普通Python程序无异。你可以使用任何Python调试工具(如pdb)在任意位置设置断点,检查中间张量的值,这使得开发和调试过程极为便捷。
2. 支持可变结构模型:
对于结构可能根据输入数据而变化的模型(如递归神经网络RNN,其循环步长可变),动态图可以自然地处理。图的构建取决于实际运行时数据,无需预先定义固定的图结构。
3. 更快的原型开发速度:
研究者和开发者可以立即获得操作结果,无需经历复杂的图编译阶段,从而加速了模型设计和实验迭代。
四、 动态图的“显式”控制:torch.no_grad()与detach()
虽然自动跟踪很方便,但有时我们需要控制梯度计算以提升性能或实现特定功能。
with torch.no_grad()::在该上下文管理器内的所有计算都不会被记录在计算图中,常用于模型推理或更新参数时的中间计算,能显著节省内存。tensor.detach():返回一个与原始张量共享数据但分离了计算历史(grad_fn=None)的新张量。常用于固定模型某一部分的参数,或准备用于不需要梯度的计算的数据。
五、
PyTorch的动态计算图机制是其设计的精髓所在。它将图的构建与代码执行融为一体,提供了无与伦比的灵活性和易用性,特别适合需要快速迭代的研究场景和模型结构复杂的任务。理解计算图如何动态生成、跟踪以及如何利用autograd进行梯度反向传播,是掌握PyTorch并高效进行人工智能软件开发的重要基础。通过熟练运用requires_grad、backward()以及梯度控制上下文,开发者可以完全掌控模型的训练过程,在灵活与效率之间找到最佳平衡点。
(本文由【aidanmo的博客】CSDN博客提供的人工智能学习笔记整理而成,旨在分享PyTorch核心机制的理解。)